الـ Crawling وتحسين محركات البحث
.jpg)
أصبحت محرّكات البحث في يومنا هذا الأداة الرئيسية المستخدمة للإبحار في عالم الإنترنت الواسع، نظرًا لما توفّره من جهد ووقت للعثور على المعلومات المختلفة. إذ ما عليك سوى أن تكتب سؤالك على أحد المحرّكات مثل Google أو Bing أو غيره، لتظهر لك آلاف بل ملايين النتائج في غضون ثوانٍ قليلة.
وحتى تصل إليك هذه النتائج خلال هذا الوقت القصير، تمرّ عملية إضافة المعلومات إلى محرّكات البحث بخطوات ثلاث رئيسية كالتالي:
- الـ Crawling: وهي عملية تصفّح الشبكة العالمية بحثًا عن أيّ محتوى جديد تمّ إضافته على الإنترنت.
- الـ Indexing: وفيها يتمّ فهرسة المحتوى الجديد وتنظيمه وتخزينه في قاعدة بيانات ضخمة لمحرّك البحث، تعرف بفرس محرّك البحث. ومن أمثلتها فهرس جوجل المسمى Caffeine.
- الـ Ranking: وهي الخطوة الأخيرة التي يتمّ فيها ترتيب المحتوى وعرضه لمستخدم الإنترنت بناءً على مدى علاقته بالاستعلام المطروح (السؤال أو الـ Query الذي أدخله الباحث في محرّك البحث).

اعرف المزيد عن هذا الموضوع من خلال قراءة مقالنا المفصّل حول كيفية عمل محركات البحث.
قد تتساءل الآن حول كيفية الاستفادة من هذه الخطوات الثلاثة لتحسين موقع الويب الخاص بك ورفع ترتيبه في صفحات نتائج البحث.
في الواقع يمكنك فعل الكثير في هذا الشأن، تستطيع مثلاً أن تمنع الـ Crawlers من العثور على بعض الصفحات في موقعك. أو تطلب من محرّكات البحث تجنّب فهرسة جزء من محتوى موقعك الذي قد يؤثر سلبًا على ترتيبك. كما يمكنك أيضًا أن تعدّل محتوى الموقع بطريقة تسهّل على محرّكات البحث فهمه وفهرسته. وكلّ ذلك يصبّ في مصلحة موقعك ويؤدي مع مرور الوقت إلى رفع ترتيبه في صفحات نتائج البحث.
سنتعرّف في مقال اليوم على الـ Crawling بتفصيل أكبر وكيفية الاستفادة منه في تحسين موقعك والمحتوى الجديد فيه ليتمّ رؤيته من قبل محرّكات البحث المختلفة.
ملاحظة:
سنركّز في مقالنا على محرّك البحث Google كونه الأشهر ويستحوذ على ما نسبته 90% من جميع عمليات البحث التي تجري على شبكة الإنترنت.
كيف أعرف أن المحرّك البحث قد عثر على موقعي الإلكتروني من خلال الـ Crawling؟
التأكد من أنّ صفحة الويب أو موقعك الإلكتروني الخاص قد تمّ الوصول إليها من قبل روبوتات محرّكات البحث (Crawlers) هو الخطوة الأولى لظهور هذه الصفحة أو الموقع في صفحة نتائج البحث SERP.
إن كنت تملك موقعًا إلكترونيًا بالفعل، فمن المستحسن أن تبدأ بأخذ فكرة عامّة حول عدد الصفحات/ الأجزاء من موقعك التي تمّ الوصول إليها من قبل الـ Crawlers، حيث يساعدك ذلك على معرفة ما إذا كان Google يصل إلى جميع الصفحات التي تريد له أن يصل إليها، وأنه لا يرى الأجزاء من موقعك التي لا ترغب في أن يتمّ العثور عليها.
إحدى الطرق البسيطة للقيام بذلك هي كالتالي:
- اكتب في خانة البحث في Google ما يلي: "site:yourdomain.com"، واستبدل عبارة "yourdomain.com" بعنوان موقعك الإلكتروني. مثلا: "site:for9a.com".
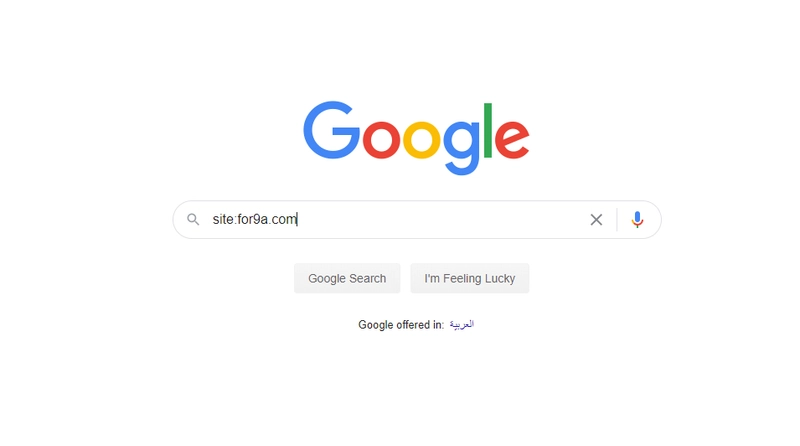
- سيعرض لك Google جميع صفحات الويب الموجودة في الموقع الإلكتروني والتي تمّ العثور عليها وحفظها خلال عملية الزحف crawling والفهرسة Indexing.
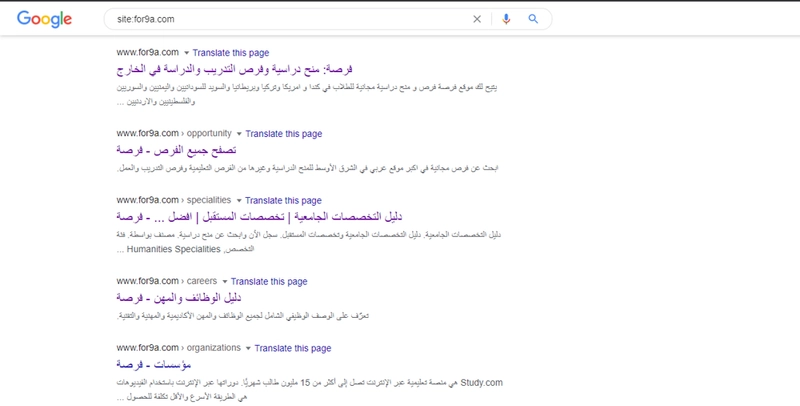
- انظر إلى رقم النتائج الذي يعرضه لك Google في أعلى الصفحة. صحيح أنّه ليس رقمًا دقيقًا، لكنه مع ذلك يعطيك فكرة قويّة حول عدد الصفحات التي تمّ فهرستها، وكيفية ظهورها في نتائج البحث.
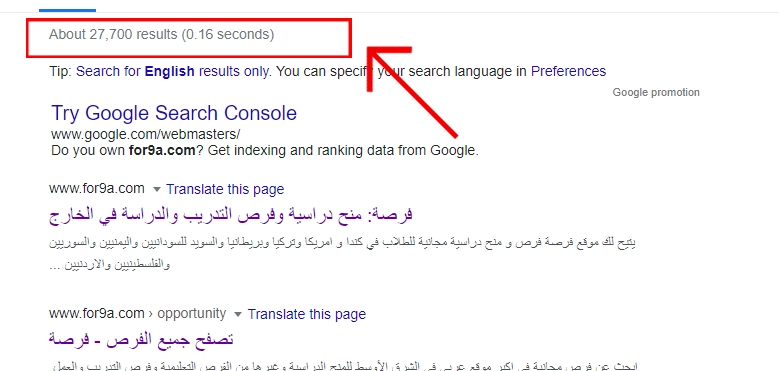
في حال رغبت في الحصول على نتائج أكثر دقّة، يمكنك إلقاء نظرة على تقرير تغطية الفهرسة Index Coverage في خدمة Google Search Console. وهي خدمة تتيحها شركة جوجل لمشرفي مواقع الويب تقدّم لهم تقارير حول الموقع الإلكتروني الخاص بهم وأدائه بشكل عام.
من خلال هذه الأداة، تستطيع تحديث خريطة موقعك الإلكتروني Sitemape باستمرار ومتابعة عدد الصفحات التي تمّ إضافتها إلى فهرس جوجل أوّلاً بأوّل. حيث يمكنك فتح حساب جديد على الفور إن لم تكن تملك واحدًا بعد.
في حال لم تظهر صفحات الويب الخاصة بك في أيّ مكان على شبكة الإنترنت، قد يعود السبب إلى واحد ممّا يلي:
- لا يزال موقعك الإلكتروني أو صفحات الويب هذه جديدة ولم يتمّ الزحف إليها/ العثور عليها بعد.
- لم يتمّ الإشارة إلى موقعك من قبل أيّ مواقع إلكترونية خارجية.
- بنية (هيكلة) موقعك الإلكتروني تجعل من عملية استكشافه وجمع المحتوى (Crawling) أمرًا صعبًا على زاحف الويب Crawler وبالتالي غير فعّالة.
- يحتوي موقعك على كود خاص اسمه (Crawler Directives) والذي يعيق عمل محرّكات البحث (سنتطرّق للحديث عنه بتفصيل أكبر لاحقًا في المقال).
- تمّ فرضُ عقوبة على موقعك من قبل Google لاستخدامه تكتيكات واستراتيجيات خاطئة أو غير مرغوب فيها.
اقرأ أيضًا: قواعد كتابة الويب | 5 طرق لتفادي كتابة محتوى لا يقرأه أحد
وضّح لمحّركات البحث طريقة الزحف في موقعك
في حال استعملت Google Search Console أو طريقة "site:domain.com" لرؤية المحتوى المفهرس على جوجل، ولاحظت عدم وجود بعض الصفحات المهمّة، أو وجود صفحات لا ترغب في أن تتم فهرستها، يمكنك القيام ببعض الأمور التي توضّح لمحرّك البحث Google طريقة الزحف على موقعك وفهرسة المحتوى الموجود عليه.
هكذا ستتحكّم فيما يتمّ تخزينه في فهرس جوجل وبالتالي فيما يُعرض للمستخدمين على شبكة الإنترنت. ولتعرف كيف يتمّ ذلك، تابع معنا قراءة المقال.
كيف أمنع الـ Crawlers من الوصول إلى جزء معين في موقعي الإلكتروني؟
يحرص الكثير من أصحاب المواقع الإلكترونية على أن يعثر Google على جميع الصفحات المهمّة ويخزّنها في فهرسه الكبير، لكنهم في غالب الأحيان ينسون حقيقة أنّ هنالك بعض الصفحات أيضًا التي لا يرغبون في أن يجدها زاحف الويب Googlebot، والتي قد تشمل على سبيل المثال لا الحصر:
- صفحات تتضمّن محتوى قليل أو غير مكتمل.
- روابط الصفحات المكرّرة (التي تظهر نتيجة استخدام خيارات الترتيب والفرز sort-and-filter في مواقع التسوق مثلاً).
- الصفحات التجريبية.
- الصفحات التي يتم الوصول إليها وعرضها عند استخدام كود خصم معيّن مثلاً.
يمكنك أن تخبر Googlebot أو غيره من زواحف الويب عن الصفحات أو الأجزاء من موقعك التي لا تريد لها أن تُخزّن في فهرس محرّك البحث من خلال ما يُسمّى بالـ Robots.txt.
ما هو الـ Robots.txt؟
الـ Robots.txt هي ملفات موجودة في موقعك الإلكتروني ويمكن تشبيهها بأنها دليل الاستخدام الذي تتبّعه زواحف الويب crawlers في عملية استكشاف الموقع وجمع المحتوى منه، حيث يتمّ اخبار زاحف الويب في هذه الملفات عن الأجزاء أو الصفحات التي عليه أن يتجاهلها بالإضافة إلى تحديد سرعة الزحف على الموقع أيضًا.
يمكنك رؤية ملف الـ Robots.txt لأي موقع من خلال كتابة الآتي في خانة البحث على جوجل:
yourdomain.com/robots.txt
مع الحرص على استبدال "yourdomain.com" بعنوان الموقع الذي تريده.
ألقِ نظرة على الصورة أدناه والتي توضّح ملف الـ Robots.txt، لموقع Buzz Feed مع شرح ما يعنيه كلّ جزّء.
.png)
كيف يتعامل Googlebot مع ملفات Robots.txt؟
هنالك ثلاث احتمالات لذلك:
- إن لم يعثر زاحف الويب Googlebot على ملف robots.txt في الموقع سيباشر على الفور بعملية الـ Crawling لكلّ محتوى الموقع.
- إن عثر على ملف robots.txt في الموقع، سيلتزم بما ورد فيه من إرشادات ويقوم بعملية الـ Crawling لمحتوى الموقع الذي سُمح له بجمعه وفهرسته.
- في حال حدث خطأ ما أثناء محاولة زاحف الويب Googlebot الوصول إلى ملف robots.txt، ولم يتمكّن من تحديد ما إذا كان هذا الملف موجودًا أم لا، سيغادر الموقع على الفور دون القيام بعملية الزحف.
هل تتقيّد جميع زواحف الويب بإرشادات الـ robots.txt؟
الجواب هو لا. فليست جميع زواحف الويب برامج ذات نوايا حسنة. قد يلجأ البعض من قراصنة الإنترنت لبناء زواحف ويب تخالف هذه التعليمات. بل قد يستخدمها البعض للعثور على المكان الذي تخفي فيه المحتوى الهامّ والخاصّ بك، ومن ثمّ سرقته.
قد ترى أنّه من المنطقي أن تمنع وصول الـ Crawlers إلى بعض الصفحات الخاصّة، مثل صفحات الملف الشخصي التي تحتاج إلى تسجيل دخول، أو صفحات مدير الموقع، لكن توضيح مكان هذه الصفحات من خلال وضع عنوان الـ URL في ملف robots.txt متاح للجميع على شبكة الإنترنت يتيح المجال أمام أصحاب النوايا السيئة للعثور على هذه الصفحات بسهولة أكبر.
بدلاً من ذلك، يفضّل أن تحمي المعلومات والصفحات المهمّة بكلمة سرّ مناسبة، وإضافة وصف Noindex عند برمجة صفحة الويب هذه.
اقرأ أيضًا: كل ما تحتاج معرفته حول كتابة الويب
الـ URL parameters وعملية الزحف
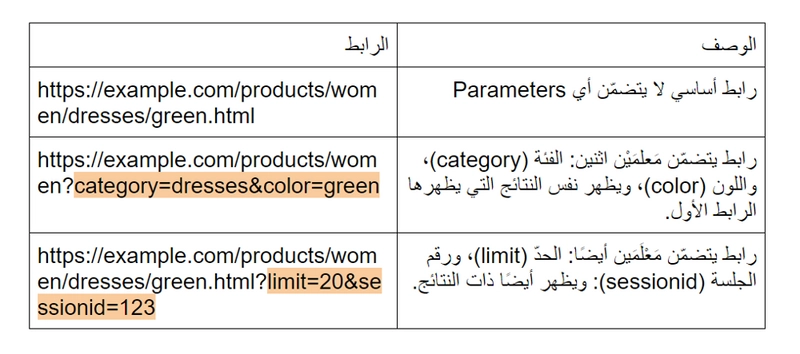
تعرض بعض المواقع الإلكترونية (وخاصّة مواقع التجارة الإلكترونية) نفس المحتوى في عدّة صفحات ويب وبعناوين URL مختلفة، وذلك من خلال إضافة مَعْلَمٍ محدّد في هذه الروابط والذي يُسمّى في اللغة الإنجليزية Parameter.
إن كنت قد تسوّقت يومًا ما عبر الإنترنت فلا شكّ أنّك استخدمت خيارات الفرز Filter، لتختار عرض منتج بلون أو مقاس محدّد… ما لم تنتبه له، هو أنّك وفي كلّ مرة تضيف خيار فرز جديد، فإن عنوان الـ URL يتغيّر قليلاً، ويُضاف إليه Parameter جديد.
ألقِ نظرة على المثال التالي الذي يوضّح استعمال الـ Parameters في رابط URL لموقع تسوّق عبر الإنترنت، حيث يشير الجزء الملوّن من الرابط إلى هذا المعلم.
لكن ما علاقة كلّ هذا بعملية الزحف Crawling؟
حسنًا، لنفترض أنّ زاحف الويب قد وصل إلى الموقع الإفتراضي الموضح أعلاه لجمع المحتوى منه، سيقوم على الأرجح بإضافة الروابط الثلاثة السابقة جميعها على الرغم من أنّها تظهر نفس النتائج ونفس المحتوى، ممّا يؤدي إلى فهرسة محتوى مكرّر وبالتالي عرض محتوى مكرّر أيضًا لمستخدمي الإنترنت، الأمر الذي يؤثر سلبًا على ترتيب الموقع.
ولحلّ هذه المشكلة، يمكننا الاستفادة من الـ Parameters وإخبار الـ Crawlers بعدم ضرورة الزحف إليها وإضافتها إلى فهرسها. حيث تستطيع ذلك من خلال خيارات تحكّم متاحة على Google Search Console كما هو موضّح في الصورة أدناه.
اقرأ أيضًا: 5 أسرار لتحسين مهاراتك في كتابة محتوى على الإنترنت وحصد آلاف المشاهدات
كيف أضمن أن تعثر Crawlers على كلّ المحتوى المهم في موقعي؟
بعد أن تحدّثنا بعض الاستراتيجيات التي يمكنك استخدامها لتُبقي زاحف الويب بعيدًا عن المحتوى غير المهم في موقعك، لنتحدّث الآن عن كيفية تحسين موقعك لضمان وصول الـ Crawlers إلى كلّ الأجزاء المهمّة منه.
من المهم أن يتصفح زاحف الويب موقعك الإلكتروني بأكمله، ويصل لجميع الصفحات المهمّة، وليس الصفحة الرئيسية فقط.
الإجابة عن الأسئلة التالية ستحقق لك هذا الأمر:
1- هل تُخفي المحتوى المهمّ وراء أوامر تسجيل الدخول؟
إن كنت تطلب من المستخدمين تسجيل الدخول Log In، تعبئة طلبات تقديم أو الإجابة عن استطلاعات رأي قبل الوصول إلى محتوى ما، فلن تتمكّن محرّكات البحث من رؤية هذه الصفحات المحمية. ذلك أنّ زاحف الويب لن يقوم بتسجيل الدخول أو الإجابة عن استطلاع الرأي!
2- هل تعتمد على صناديق البحث؟
يعتقد البعض أنّهم إذا أضافوا صندوق بحث Search Box في موقعهم الإلكتروني فسوف تتمكّن محركات البحث من العثور على كلّ المحتوى الموجود في الموقع. هذا الأمر ليس حقيقيًا إطلاقًا، فلا تعتمد عليه في جعل محتوى موقعك الإلكتروني مرئيًا للـ Crawlers.
3- هل تعرض النصوص في شكل غير نصّي؟
إن كنت ترغب في أن يتمّ العثور على نصوص معيّنة في موقعك من قبل محرّكات البحث، احرص على وضعها في صيغة نصية، حيث أن النصوص المحفوظة في صيغ أخرى كالصور أو مقاطع الفيديو لن يتمّ استكشافها من قبل زاحف الويب.
صحيح أن محرّكات البحث تحقّق تحسّنًا في التعرّف على الصور، لكن ذلك لا يعني أنّها قادرة على قراءتها وفهم محتواها بعد. لذا من الأفضل على الدوام إضافة صيغ نصية عند برمجة صفحات الويب في موقعك الإلكتروني.
4- هل يمكن لمحركات البحث متابعة التنقل في موقعك؟
تعرف بلا شكّ أن الـ Crawlers تصل إلى موقعك الإلكتروني من خلال روابط في مواقع أخرى. وحتى يستطيع زاحف الويب هذا التنقّل بين صفحات موقعك، فهو بحاجة أيضًا إلى مسار من الروابط الإلكترونية. لذا، إن كنت تملك صفحة ويب معيّنة تريد لمحرّكات البحث أن تكتشفها، ولكنك لم تربطها بأي صفحات أخرى فوجودها وعدمه في هذه الحالة واحد.
احرص على الربط بين صفحات موقعك الإلكتروني بطريقة تتيح للـ Crawlers الزحف إليها واستكشافها جميعها.
5- هل لديك بنية معلومات واضحة؟
يُقصد ببُنية المعلومات في هذا السياق عملية تنظيم وترتيب وتوسيم (Labeling) المحتوى في موقعك الإلكتروني بكفاءة ممّا يزيد من فعالية الموقع ويسهّل على المستخدم الوصول إليه.
أفضل بُنية للمعلومات هي البنية الواضحة البديهية. بمعنى آخر، يجب على المستخدم ألاّ يبذلا لكثير من الجهد في التفكير في كيفية العثور على معلومة أو صفحة معيّنة على موقعك الإلكتروني.
6- هل تستخدم خرائط الموقع Sitemaps؟
خرائط الموقع أو ملف الـ Sitemap هو بالضبط ما يبدو عليه: قائمة بجميع عناوين الـ URL الموجودة في موقعك والتي يمكن للزواحف استخدامها لاكتشاف المحتوى الخاص بك وفهرسته.
حتى تضمن وصول زاحف الويب Googlebot إلى صفحات موقعك ذات الأولوية القصوى، احرص على إنشاء خريطة واضحة لموقعك حسب معايير Google وإرسالها عبر Google Search Console.
من الجدير بالذكر أنّ خريطة الموقع لا تُغني عن ضرورة بناء موقعك بطريقة تضمن سهولة التنقل بين صفحاته، لكنها مع ذلك تساعد برامج الزحف على تتبّع مسار جميع صفحاتك المهمّة.
زاحف الويب والتعامل مع الأخطاء خلال عملية الزحف
خلال عملية الزحف في موقعك الإلكتروني، قد يواجه زاحف الويب أخطاء معيّنة Errors، حيث يمكنك استعراض هذه الأخطاء من خلال خيار "Crawl Errors" في Google Search Console. وبالتالي إصلاحها وضمان استمرار عملية الزحف بشكل سليم.
فيما يلي أنواع الأخطاء Errors التي يمكن لزاحف الويب أن يواجهها خلال عملية استكشاف موقعك الإلكتروني وكيفية تعامله معها:
1- أخطاء 4XX
والتي يتعذّر على زاحف الويب فيها الوصول إلى المحتوى بسبب خطأ 4XX. حيث أنّ هذه الأخطاء هي أخطاء عميل. بمعنى آخر، فالرابط المطلوب يحتوي على بنية سيئة أو غير صحيح.
من أشهر أخطاء 4XX نجد خطأ "404 - غير موجود" أو Not Found. والذي يظهر عندما تكتب عنوان الموقع بشكل خاطئ، أو حال حذف صفحة ويب نهائيًا، أو عملية ترحيل خاطئة للموقع Redirect.
عندما يصل زاحف الويب إلى رابط 404، لن يتمكّن من استكشافه أو الدخول إليه، وكذلك الحال مع المستخدمين الذين يغادرون الموقع في حال وصلوا إلى رابط 404.
2- أخطاء 5XX

وتحدث عندما يتعذّر على زاحف الويب الوصول إلى محتوى الموقع بسبب خطأ في الخادم Server. حيث أنّ جميع أخطاء الـ 5XX هي أخطاء خوادم. بمعنى آخر، الـ Server الذي توجد عليه صفحة الويب هذه، فشل في تلبية طلب زاحف الويب بالدخول إلى هذه الصفحة. وتحدث في الغالب عندما يستغرق الوصول إلى رابط معيّن وقتًا طويلاً بسبب مشاكل في الشبكة أو في الاتصال بالإنترنت. وغالبًا ما يتجاهل زاحف الويب محاولة استكشاف هذه الروابط في حال حدوث هذا الخطأ.
3- إعادة التوجيه Redirect

لكن ماذا لو تمّ نقل محتوى صفحة معيّنة إلى رابط آخر؟ كيف يمكنك إخبار المستخدمين ومحرّكات البحث بهذا الأمر؟
لحسن الحظ، هنالك طريقة لذلك، وهي استخدام أمر إعادة التوجيه الدائم 301 أو الـ Permanent Redirect 301
لنتفرض مثلاً أنّك نقلت صفحة من الرابط: example.com/young-dogs إلى الرابط التالي: example.com/puppies
تحتاج في هذه الحالة إلى جسر ينقل المستخدمين ومحرّكات البحث من الرابط القديم إلى الرابط الجديد، وهذا بالضبط ما يفعله أمر إعادة التوجيه الدائم Permanent Redirect رقم 301.
تجنّب استخدام سلاسل إعادة التوجيه أو الـ Redirect Chains، أيّ استخدام أمر إعادة التوجيه عدّة مرّات، نظرًا لأن ذلك يشتّت محرّك البحث وقد يحول دون استكشاف وفهرسة صفحات الويب في موقعك.
إن كان لديك صفحة example.com/1 وقرّرت نقلها إلى example.com/2، ثمّ اضطررت لنقلها مرة أخرى إلى example.com/3 فأنت بذلك قد أنشأت سلسلة إعادة توجيه. والأفضل في هذه الحالة أن تتخلّص من example.com/2 وتجري عملية النقل مباشرة من example.com/1 إلى example.com/3.
أصبحت تمتلك الآن فكرة شاملة حول كيفية عمل زاحف الويب Crawler وآليته في استكشاف المواقع وصفحات الويب. ويمكنك الآن الاستفادة ممّا تعلّمته في بناء موقعك بطريقة صحيحة تضمن أن يتمّ استكشافه والتنقل فيه بطريقة سلسلة سواءً بالنسبة لزواحف الويب أو للمستخدمين، وهذا جزء من عملية تحسين محرّكات البحث SEO على الصعيد التقني، أمّا لمعرفة المزيد حول كيفية تحسين موقعك على صعيد المحتوى، فلا تتردّد في قراءة مقالنا حول قواعد الـ SEO في كتابة المحتوى.
لا تنس التسجيل في موقعنا ليصلك كلّ جديد من المقالات والفرص المميزة.
المصدر: moz.com، support.google.com
اقرأ أيضًا: 12 سبب لتبدأ بتطبيق تقنيات الـ SEO على موقع الويب الخاص بك
اقرأ أيضًا: كل ما تحتاج معرفته حول تحسين محركات البحث SEO